.png)

Software Engineering Intelligence
-
 Intelligence Engine
Intelligence Engine
On-demand exhaustive AI-analysis
-
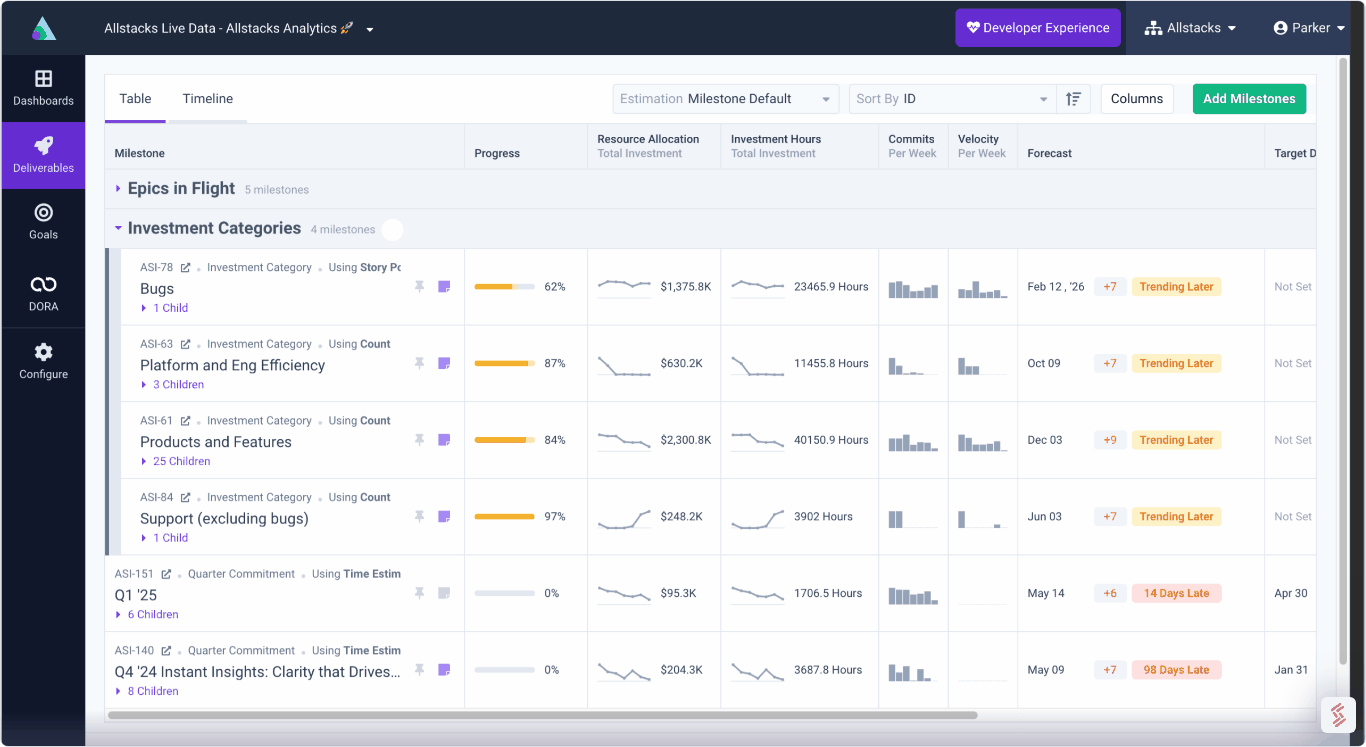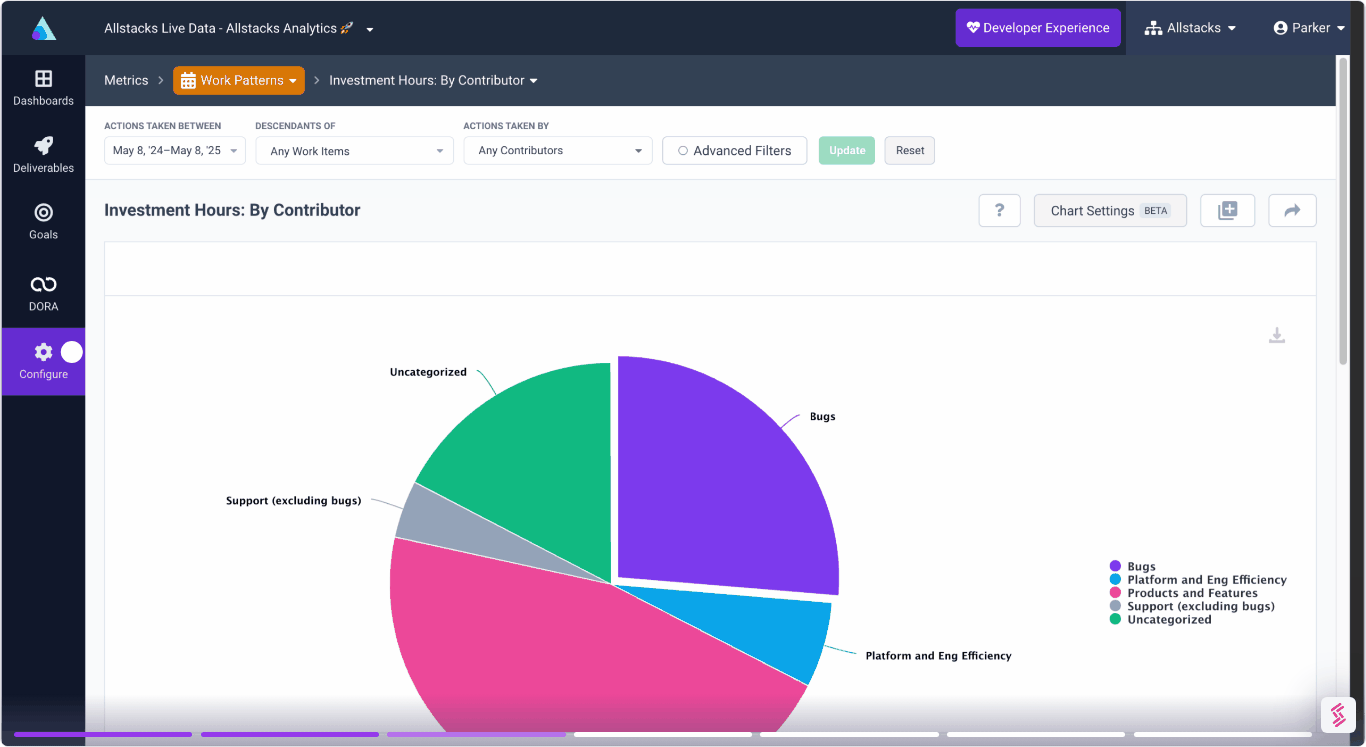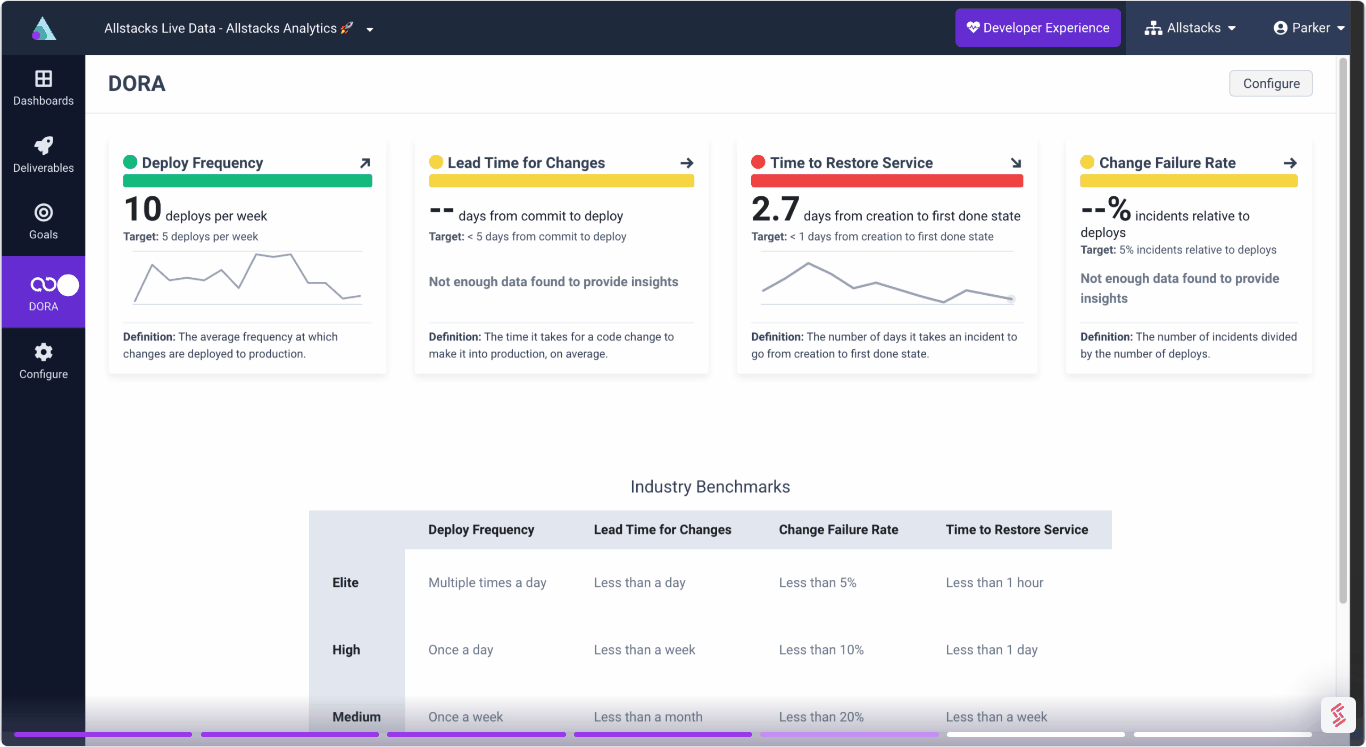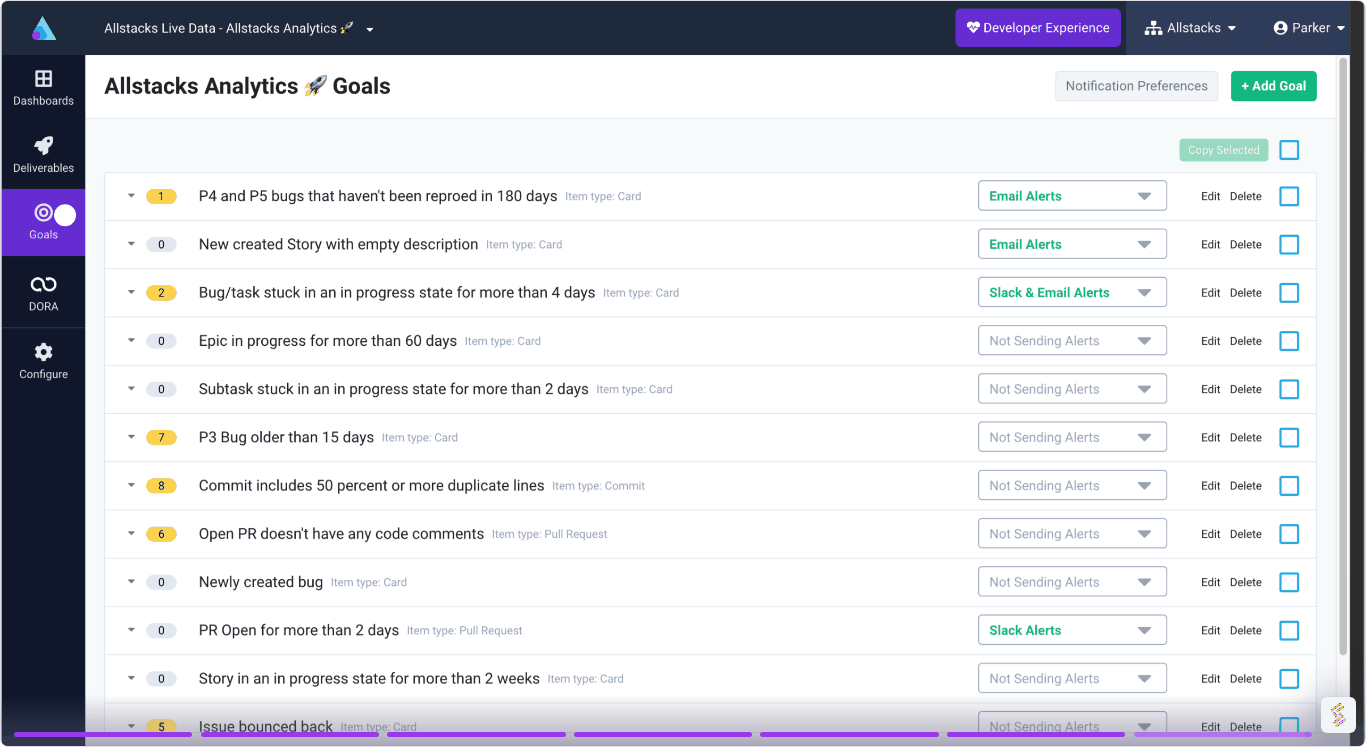
 Engineering Investment
Engineering Investment
Complete visibility into time & dollars spent
-
 360º Insights
360º Insights
Create meaningful reports and dashboards
-
 Project Forecasting
Project Forecasting
Track and forecast all deliverables
Product Management
-
 Product Studio
Product Studio
Requirements building for agentic development
Software Capitalization
-
 R&D Capitalization Reporting
R&D Capitalization Reporting
Align and track development costs
Strategy & Thought Leadership
Context Graphs Are the Next Data Lakes. Here's How to Avoid Repeating the Same Mistake.
What is a context graph, and why are most enterprise builds already following the same path that turned data lakes into swamps? Here's the architecture that delivers value.

Every decade or so, the enterprise falls in love with a new answer to the same question: How do we make sense of all our data?
In the 2010s, that answer was data lakes. In the 2020s, it is context graphs. A context graph is a data layer that stores both the entities and the relationships between them: how they connect, how those connections change over time, and what those patterns mean. Where a data lake stores records, a context graph maps meaning. That distinction sounds incremental. The consequences are not, and neither is the way most organizations are currently building them.
The original pitch for data lakes made sense: stop worrying about schemas, collect everything in one place, and let the use cases emerge once the data is accessible. Industry analyses at the peak of that era put failure rates above 80%, mostly because implementations took a "build it and they will come" approach. Heavy investment in infrastructure without first defining the specific outcomes the lake was supposed to produce. The data showed up, but very few organizations had done the work to know what they would do with it once it arrived.
Now the enterprise is falling in love again, this time with context graphs. The pattern feels familiar enough to examine closely, so as not to repeat the same mistakes.
What Went Wrong with Data Lakes and Why the Pattern Is Repeating
The easy narrative is that data lakes failed. That misses the point. Data lakes worked. They ingested data at scale, stored it cheaply, and made it accessible. What they did not do, in most implementations, was connect that data to the decisions people actually needed to make.
The problems were consistent across organizations that struggled. Infrastructure came before the use case, so nobody was responsible for turning raw material into something useful. Data accumulated without context, and every consumer ended up reconstructing meaning on their own, often reaching different conclusions from the same underlying data. Governance either did not exist or was so heavy-handed that it defeated the purpose. Ownership was organized by layer (storage, compute, access) rather than by outcome, so nobody owned the central question: Does this actually help someone make a better decision?
None of this was inevitable. Organizations that started with clear use cases built data lakes that delivered real value. The ones that started with infrastructure and assumed the value would follow produced the cautionary tales.
Context Graphs Are a Better Starting Point, but Not Immune to the Same Pattern
A context graph takes a different approach. Where a data lake says "here's a record," a context graph says "here's a record, and here's how it connects to this person, that project, this team's OKR, and the deployment that happened last Tuesday." It does not just store entities. It maps how they relate, how those relationships change over time, and what those patterns mean.
What is a context graph? A context graph is a structured data layer that encodes entities and the relationships between them, including the causal and temporal logic that explains why those relationships exist. A data lake stores what happened. A context graph stores what it means and what it connects to. The simplest analogy is a phonebook versus a social network: both have names and numbers, but only one tells you how people actually connect.
Context graphs are becoming the foundational data layer for enterprise AI, and for agents in particular. Agents that take action need to understand not just what data exists, but what it means, who it affects, and how it connects to everything around it. Without that connective tissue, agents hallucinate, make shallow recommendations, and miss the dependencies across teams and systems that determine whether work actually ships.
Vendors building horizontal knowledge graphs have made this case clearly. The clearest example is the enterprise-wide graph that vendors like Glean have built, with 100+ connectors spanning every major enterprise application and a unified model of how the organization works. Their thesis, that context is the foundation for AI that can do real work and not just answer questions, is right.
But here is where the data lake experience matters: context graphs could follow the same unintentional path. The same "build it and they will come" instinct is already showing up. Connect everything, map every relationship, serve every use case from one graph, and assume that more connections will produce more intelligence. That assumption is the same one that turned lakes into swamps.
The Accumulation Trap
Data lakes did not set out to become swamps. They became swamps gradually, one well-intentioned ingestion at a time, as teams added data without a clear picture of how it would be consumed or by whom.
I am watching something similar play out right now with context graphs, particularly in banking and insurance. We are talking to a number of large enterprise organizations that are embarking on what feel like Sisyphean efforts to build thin, horizontal context graphs that connect as much data as possible. The theory makes sense on the surface: if an agent can reach any piece of data in the organization, it should be able to answer any question. So they are pouring resources into figuring out how to connect their systems, how to map one data source to another, how to make sure an agent can traverse from point A to point B.
What most of them are not doing is working backward from a specific problem. There is no particular use case driving the architecture. Nobody has said: "We need to answer this question for this person, and here is the data path required to get there." The connectivity is the project. And the assumption is that once the connections exist, the value will follow.
Connected architecture has real value. Knowing that data can be reached is better than having it siloed. But connectivity on its own does not give an agent the ability to reason about what it finds. A graph that connects an engineering team's Jira board to an HR system to a financial ledger has a lot of edges. But an agent traversing those edges still has no understanding of why a delivery is late, what caused it, or what to do about it. The connections exist, but they do not carry the directionality or causal logic that comes from building a graph around a specific domain and the problems that domain actually needs to solve.
Context needs to come in layers, with different layers serving genuinely different purposes.
Horizontal vs. Vertical Context Graphs: Two Layers, Different Jobs
The enterprise needs two kinds of context graphs, different enough in purpose and ownership that they will almost certainly be built by different teams.
A horizontal knowledge graph is the enterprise-wide layer. It needs to connect a lot of systems and make data reachable. That’s a real engineering challenge. Vendors like Glean have built this layer after many years. Enterprises want to own it, and many will eventually buy it. The relationships the horizontal graph maps are relatively flat: this document belongs to this person, this person belongs to this team, this team works on this project. The graph is wide, but the edges are thin. They tell you what’s connected to what, not what those connections mean in the context of a specific domain.
A vertical context graph has to encode an understanding of the domain itself: what kinds of problems exist in software delivery, where they originate, how they propagate, and what sequence of events constitutes a risk vs. normal variation. That understanding is domain expertise that happens to express itself as a data model, and it’s the part that takes years to get right.
The difference between these two layers comes down to what I think of as the informed walk versus the random walk.
In a random walk, an agent moves from node to node without any sense of direction. It can reach any piece of data, but it has no basis for deciding which path is likely to lead somewhere useful. A horizontal graph enables that kind of walk by making data reachable. That is valuable. But when an agent needs to produce a useful answer in a single workflow, in real time, for a person waiting for a response, reachability is not enough.
An informed walk is different. The agent has prior domain understanding that shapes how it moves through the graph. It knows that when a PR has been sitting in review for three days and the linked work item is on a critical path, the next place to look is the reviewer's workload and the sprint deadline, not the HR org chart. The domain knowledge reduces the number of traversals needed to reach a useful conclusion. Where a random walk needs repetition to converge, an informed walk gets there in a single pass, because the graph itself encodes enough about the problem space to guide the agent toward the right answer the first time.
That is what makes a vertical context graph hard to build and hard to replicate. You need temporal modeling that understands a PR opened Monday, sat in review for three days, and deployed Friday, and that this sequence tells you something specific about delivery risk and team capacity. You need causal inference that can determine a blocked dependency in Team Y is the cause of a delay in Team X, traced through the dependency chain across work items, branches, and deployment pipelines. That kind of knowledge comes from years of working inside a specific domain and building a model around the problems that domain actually needs to solve.
A horizontal graph can tell you that Team X and Team Y both exist and are working on the same initiative. What it cannot tell you is how their work intersects, where it is breaking down, and what to do about it. That is what the vertical graph is for.
Context graphs are also the data substrate that makes context engineering possible. The practice of context engineering, structuring the full information environment for an AI agent to maximize the probability of a useful output, depends entirely on what the context layer contains. You cannot engineer context you have not built. Every informed-walk capability in an AI agent is downstream of how well the context layer was constructed, which is why what AI agents actually see and act on has become one of the most consequential architectural decisions in enterprise AI.
Why Agents Need Both Layers
This is the part I think most enterprises will get wrong if they do not think about it early: the most capable agents will not run on one graph. They will need to traverse both.
Say a VP of Engineering asks: "What is the biggest risk to our Q3 delivery, and what is the business impact?"
That question requires two kinds of context to answer well.
The vertical context graph identifies that Initiative X is trending eight days late because of an upstream dependency bottleneck, that Frontend Team A is over capacity with four PRs stuck in review, and that the Checkout Service deployment is blocked. It traces the causal chain, quantifies the delay, and recommends specific engineering actions.
The business impact question needs the horizontal graph. It needs to know that Initiative X is tied to a board-level commitment, that the Checkout Service is revenue-critical for Q3, and that the VP presents to the CEO next Thursday.
An agent with access to both can compose an answer neither system could produce alone: "Initiative X is trending eight days late. Root cause is a dependency bottleneck in Team Y. This puts the Q3 revenue commitment at risk. You present to the CEO in four days. Here is a rescoping plan that recovers five of the eight days."
That answer has functional depth from the vertical graph and organizational breadth from the horizontal one. It does not come from a dashboard or a single graph. It comes from an agent that can move between both layers to connect the engineering reality to the business context. That connection is what turns engineering metrics into business decisions; it is what most context graph architectures are not yet built to support.
The same composition applies earlier in the cycle, before a single line of code is written. A product team defining next quarter's scope needs both layers to make a grounded feasibility call: the vertical graph supplies delivery history, actual team capacity, and the dependency chains that will create drag before they appear in any delivery metric. The horizontal graph supplies the board-level commitments and stakeholder priorities that constrain what can actually ship. An agent traversing both can turn "Is this initiative feasible given what we know?" from an estimate into a grounded answer, shaping and de-risking work at the planning and prototype stage rather than discovering the constraints three sprints in.
Five Rules for Building a Context Graph That Delivers Value
The data lake era left some useful lessons if we are willing to apply them.
Start from a question, not a data model. The data lakes that delivered value started with a specific use case. Context graphs should begin the same way: a specific question a specific person needs answered ("What is at risk in my portfolio and why?") and work backward from there. If a relationship does not help answer a real question, it does not belong in the graph yet.
Own the horizontal. Partner for the vertical. Enterprises should own their broad organizational knowledge graph. It is core infrastructure. But vertical context graphs encode deep domain expertise: the informed-walk logic that takes years to build correctly. That is not something you spin up with an internal team and a Jira integration.
Demand traversability, not just connectivity. The measure of a context graph is whether an agent can reliably traverse connections to reach a useful, accurate conclusion, not how many connections exist. A graph with a million edges that does not help an agent reach a useful answer is just a data lake with extra metadata. The question to ask any vendor or internal team: "Can your agents trace a root cause through this graph and recommend a specific action? Show me."
Enforce meaning at ingestion. The data lake era taught us that deferring interpretation to downstream consumers does not work at scale. Context graphs need to classify and normalize data as it enters, mapping activities to people, people to teams, teams to objectives, so that relationships are meaningful from the moment they are created. If your graph is populated with raw records instead of classified, connected entities, you are building a lake and calling it a graph.
Keep the layers composable. The horizontal and vertical graphs need to interoperate without merging. MCP is the current standard for how agents move between systems, though the protocol landscape is still evolving. The principle that matters regardless of protocol: when an agent crosses the boundary from a vertical graph into a horizontal one, it should carry inference with it. If an agent has done an informed walk through the vertical graph and identified a delivery risk caused by a dependency bottleneck, it should arrive in the horizontal layer with enough directionality to know what it is looking for: who owns the blocked initiative, what is the business priority, when does leadership need to know. The domain reasoning from the vertical graph shapes the query into the horizontal graph. That is what composability actually means here, not just that the layers can talk to each other, but that the intelligence built up in one layer informs how the agent navigates the other.
What Comes Next
Enterprises are already treating context graphs as the next major architectural shift, and the forecast data supports that view. Gartner's 2026 Magic Quadrant for Developer Productivity Insight Platforms predicts that by 2028, 60% of developer productivity platforms will act as foundational context engines, equipping agentic workflows with real-time environmental awareness, state management, robust knowledge retrieval, policy guardrails, and strict goal alignment. The horizontal infrastructure layer is coming. Most large organizations will have some version of it within a few years, whether they build it or buy it.
Most of the current focus is on delivery risk and execution monitoring. The same architecture applies upstream: context graphs that inform product planning, scope definition, and prototype decisions before work enters the build cycle are where the next wave of value will land for enterprise software teams. Teams that can ask "what is realistically buildable this quarter, given actual capacity and existing commitments?" and get a grounded answer from both layers will make fundamentally different planning decisions than teams relying on estimates.
The organizations that create real value from context graphs will be the ones that started from a problem worth solving. That is the same lesson the data lake era taught, and it is worth learning before the infrastructure investment lands.
We have spent seven years building the vertical context graph for software delivery. If your engineering organization is evaluating what your AI agents actually need to act on initiative-level risk and develop better quality software, we are glad to walk through what that looks like in practice.
Content You May Also Like

Your Jira Tickets Are Killing Your Velocity
Bad Jira tickets cascade into rework, delays, and missed expectations. Here's how AI-powered spec readiness fixes the input before your sprint starts.
Read More
![[WEBINAR] Your Jira Tickets are Killing Code Quality | Allstacks](https://www.allstacks.com/hubfs/webinar-promo-linkedin-square.png)
[WEBINAR] Your Jira Tickets are Killing Code Quality | Allstacks
Discover how Allstacks automates requirements quality review to ensure complete, scalable AI-driven software delivery. Learn proven methods to...
Read More

Are You Building for Humans or for Agents?
Building agentic infrastructure for AI agents, not humans. ZipRecruiter's Arthur Frayman on what changes in platform engineering.
Read More