.png)







Strategy & Thought Leadership
Along with Commit Frequency and Commit Volume, Commit Size is the final basic metric around the number of lines of code a developer creates.
/new-Path266.svg)
The size of individual commits is one of the most significant contributors to risky code. Even with a formal code review and unit testing policy, the larger a change, the easier it is to miss something. The general advice for commit size is just like Einstein said, it should be made as small as possible, but no smaller. Easy, simple to understand changes are more likely to both show errors and lead to developers inadvertently fixing errors that arise from complexity before they even commit.
An example of how Allstacks uses Commit Size
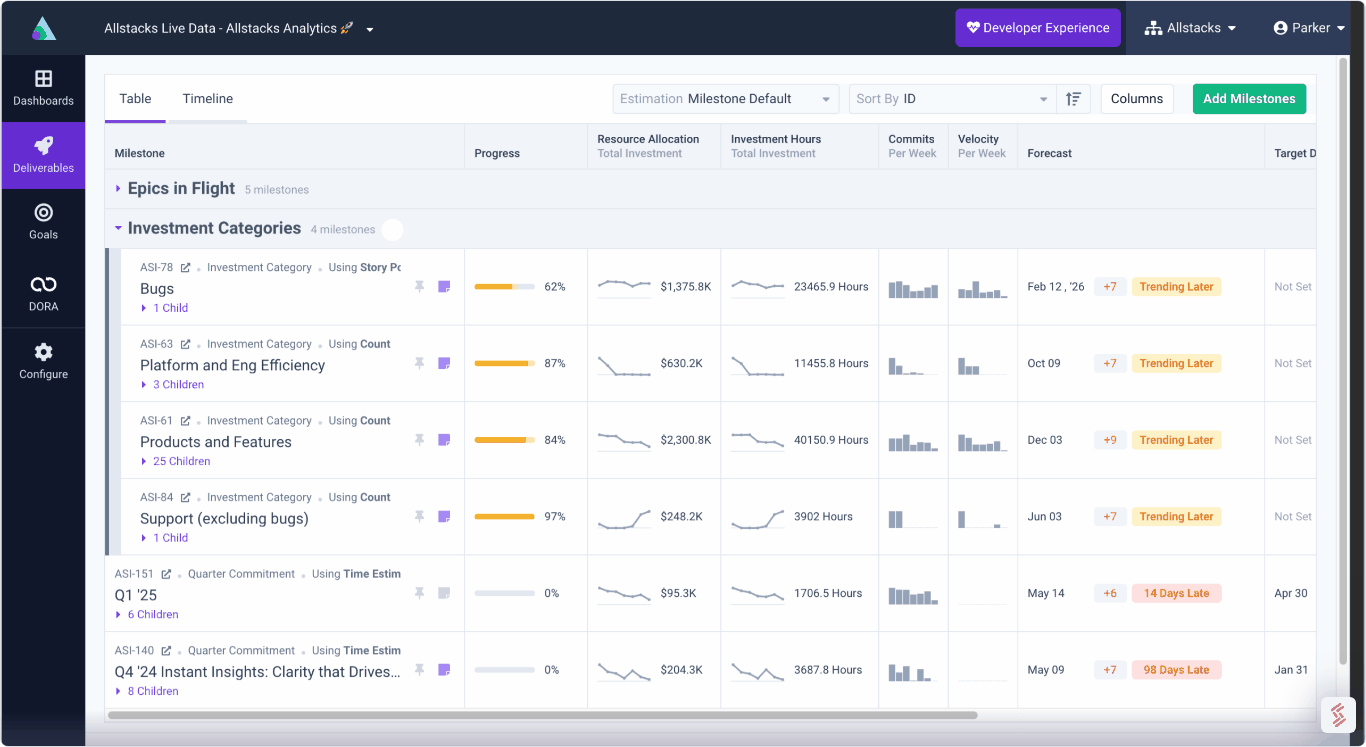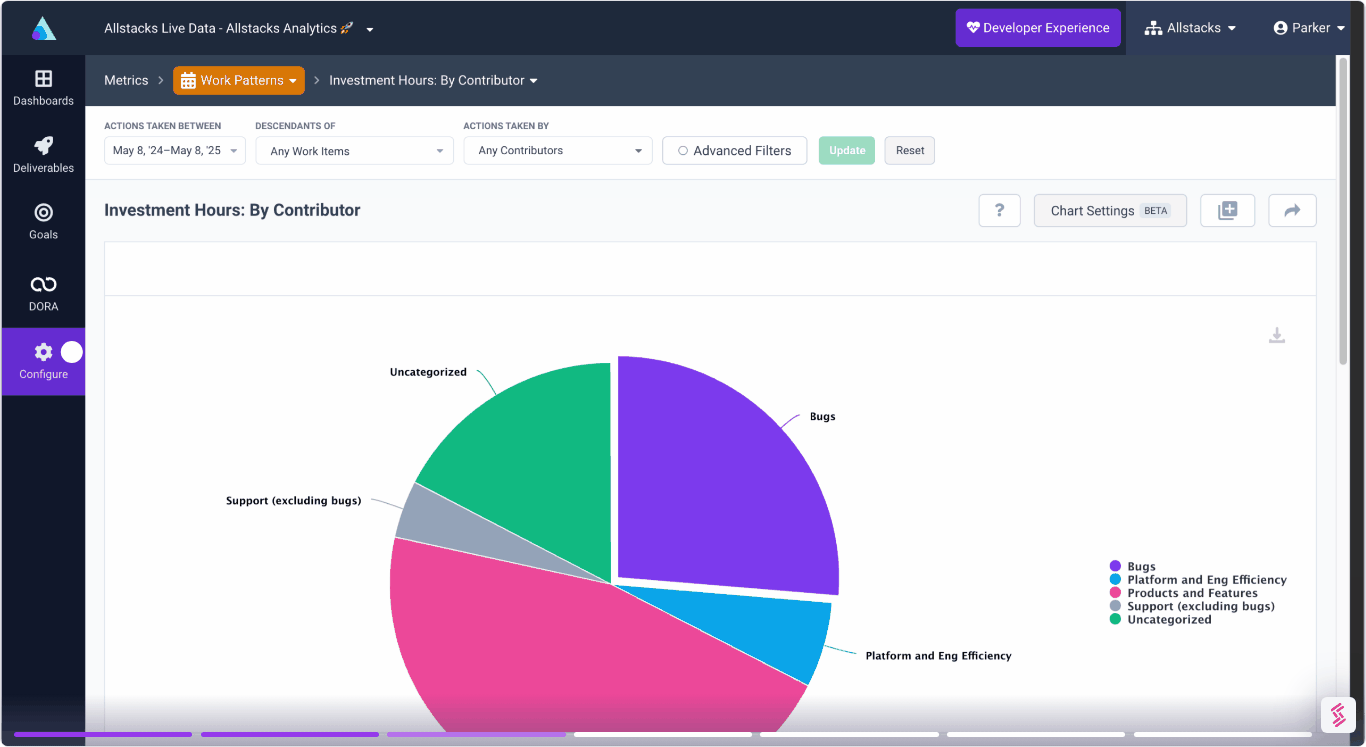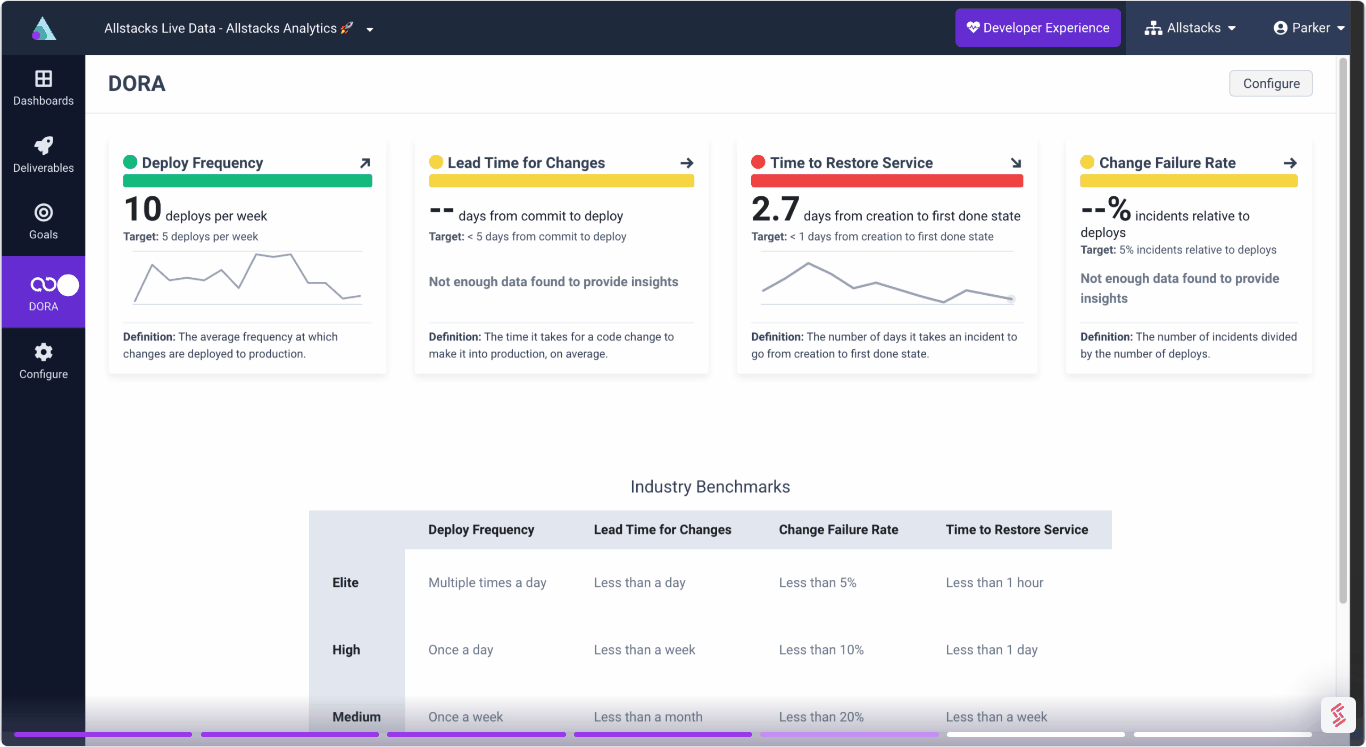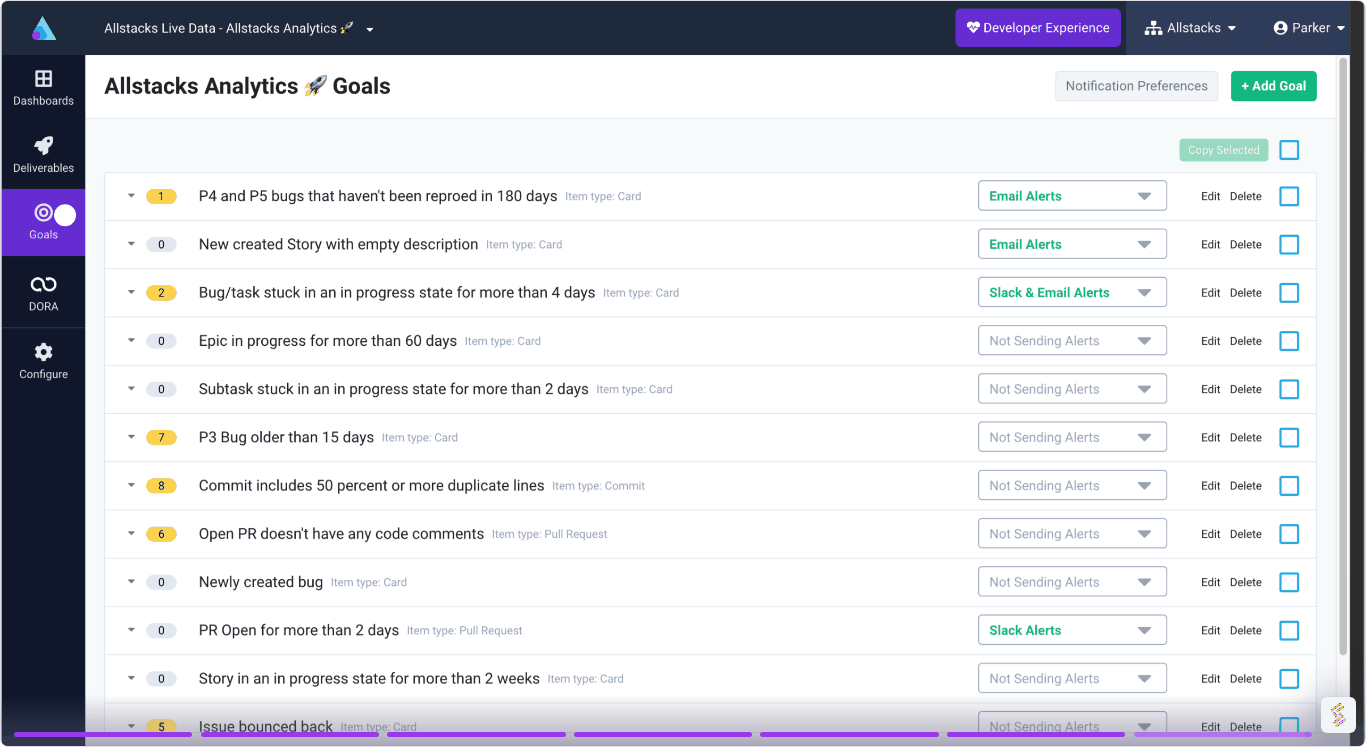
The below screenshot (from Allstacks platform) is from the Allstacks front-end team and shows the commit size of our front-end team for the first half of 2021. We are seeing a nice trend down, and the range is becoming more consistent.
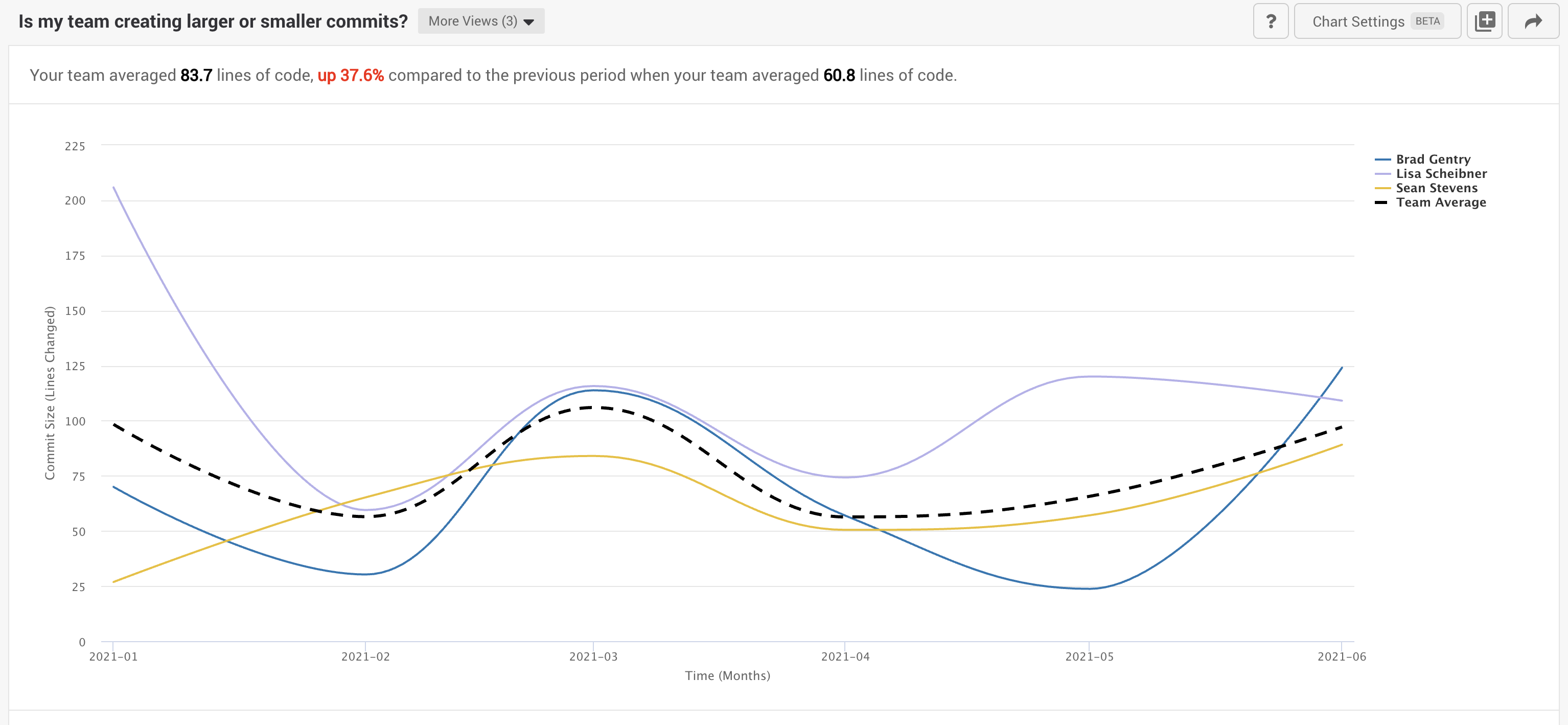
In the alert, you see that compared to the second half of 2020, the team has increased the lines of code written by 37.6% which seems like a significant variance worth investigating.

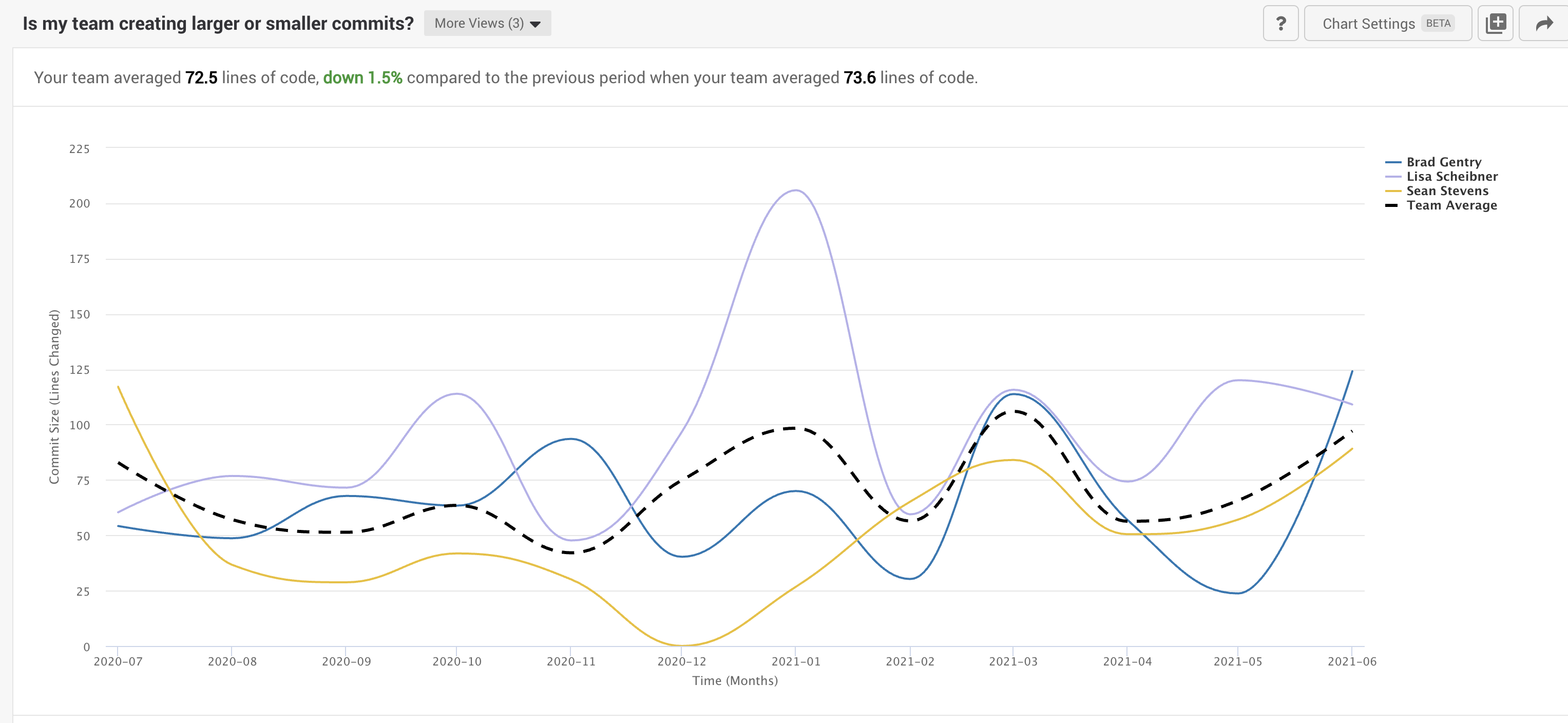
This could be a symptom of multiple factors, so we expanded the date range to see what happened over the last 12 months. While the range is pretty narrow, you can see the potential impact of holiday schedules shifting the assignments and workload that accounts for increased commit size in 2021.
A good rule of thumb for Commit Size
Each commit should be able to fit in the working memory of a developer. It’s challenging to place an ideal number on how large a commit should be, but each commit should fit in the working memory of a developer. Otherwise, you run the risk of bugs or issues being missed in code review, or worse, production.
This is also another metric that depends on your technology stack and your team. An excellent assembly team may turn out ten times the size features of an Alexa Skill team, but it’s essential to identify your nexus of size vs. risk, where your value is maximized, and stay there.
This is also a good metric to show developer growth and team development. High-performance engineering teams strive to improve by making smaller, less risky commits, which is actually challenging for more junior developers. Helping to instill good coding practices by measuring what people are doing is one of the best ways to take your team out of the dog house and to rockstar status within your organization.
Ready to see it for yourself? Getting started starts with a personalized demo.
A note about engineering metrics in general
We do not believe the performance of an engineering team can be based on a single engineering metric. However, a set of metrics together can give engineering leaders, managers, and developers greater context into how teams are doing and where they are getting blocked so you can proactively respond and adjust your plan accordingly to ensure on-time delivery.