.png)

Software Engineering Intelligence
-
 Intelligence Engine
Intelligence Engine
On-demand exhaustive AI-analysis
-
 Engineering Investment
Engineering Investment
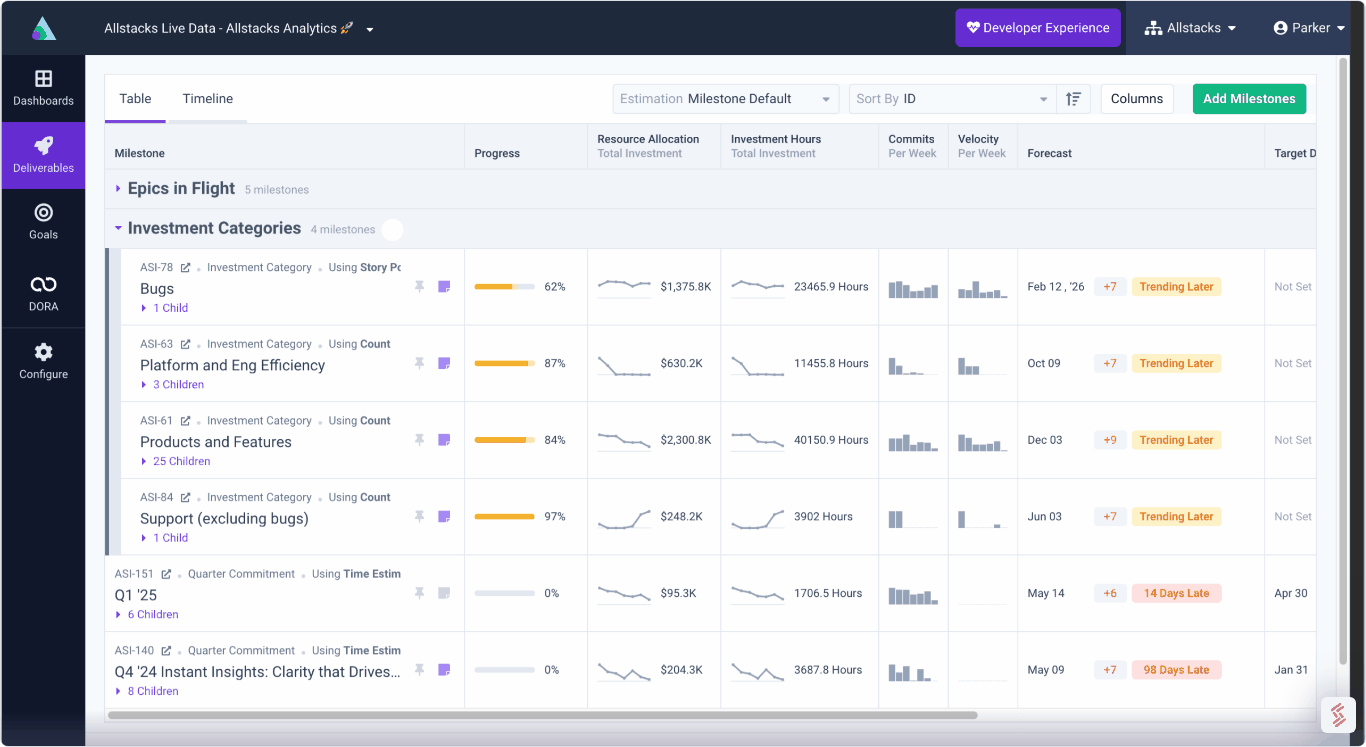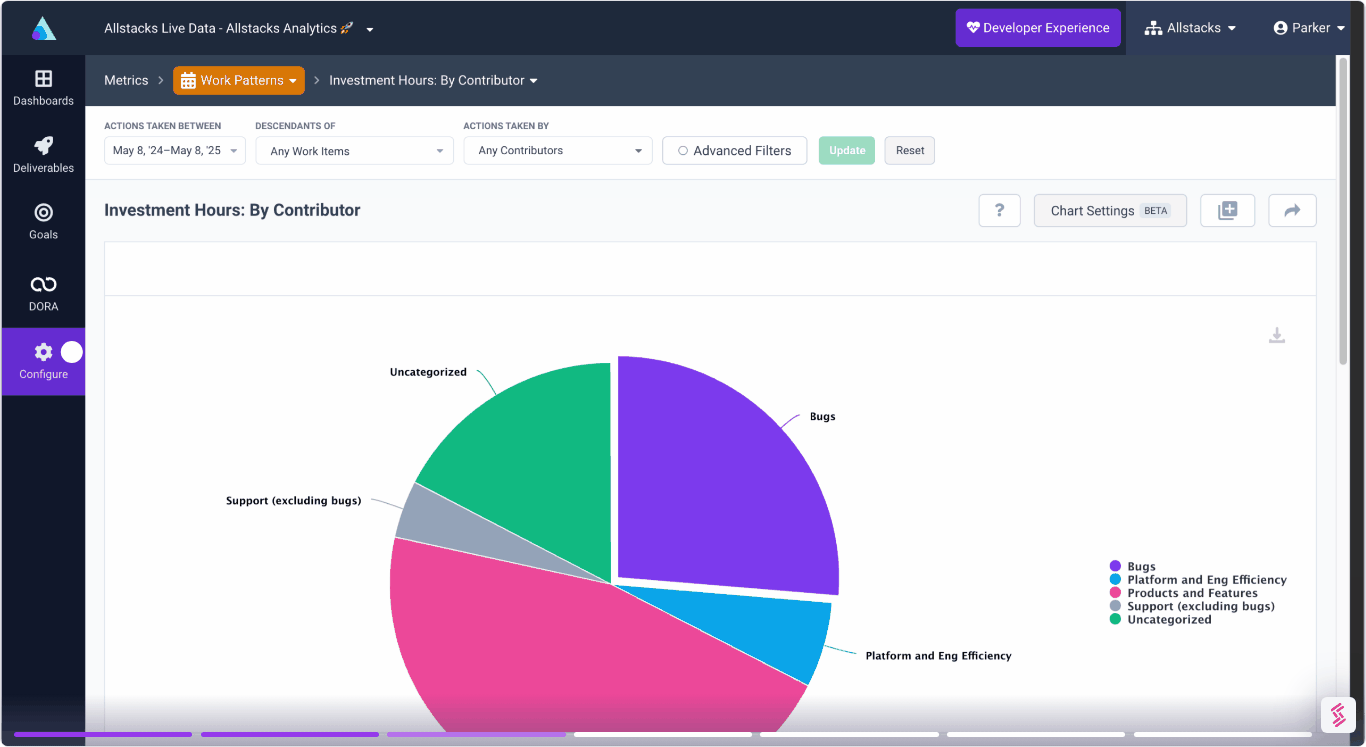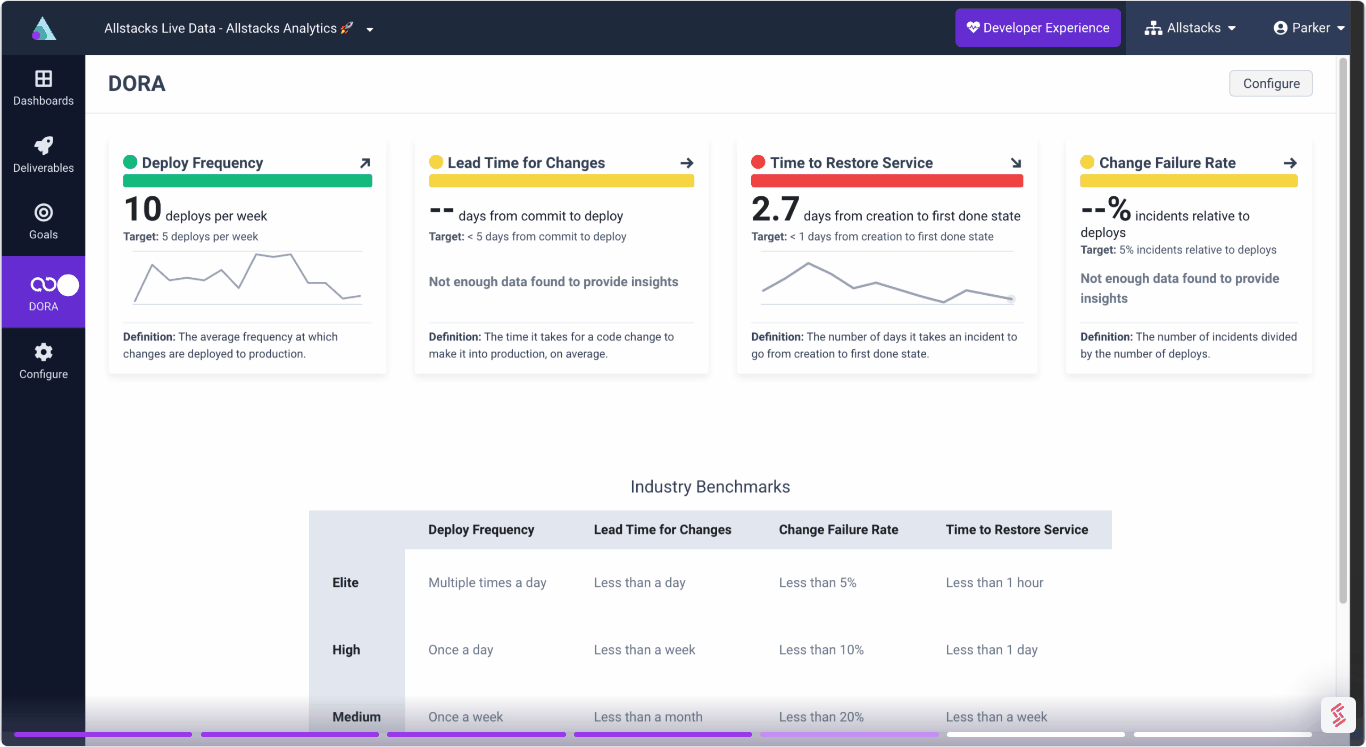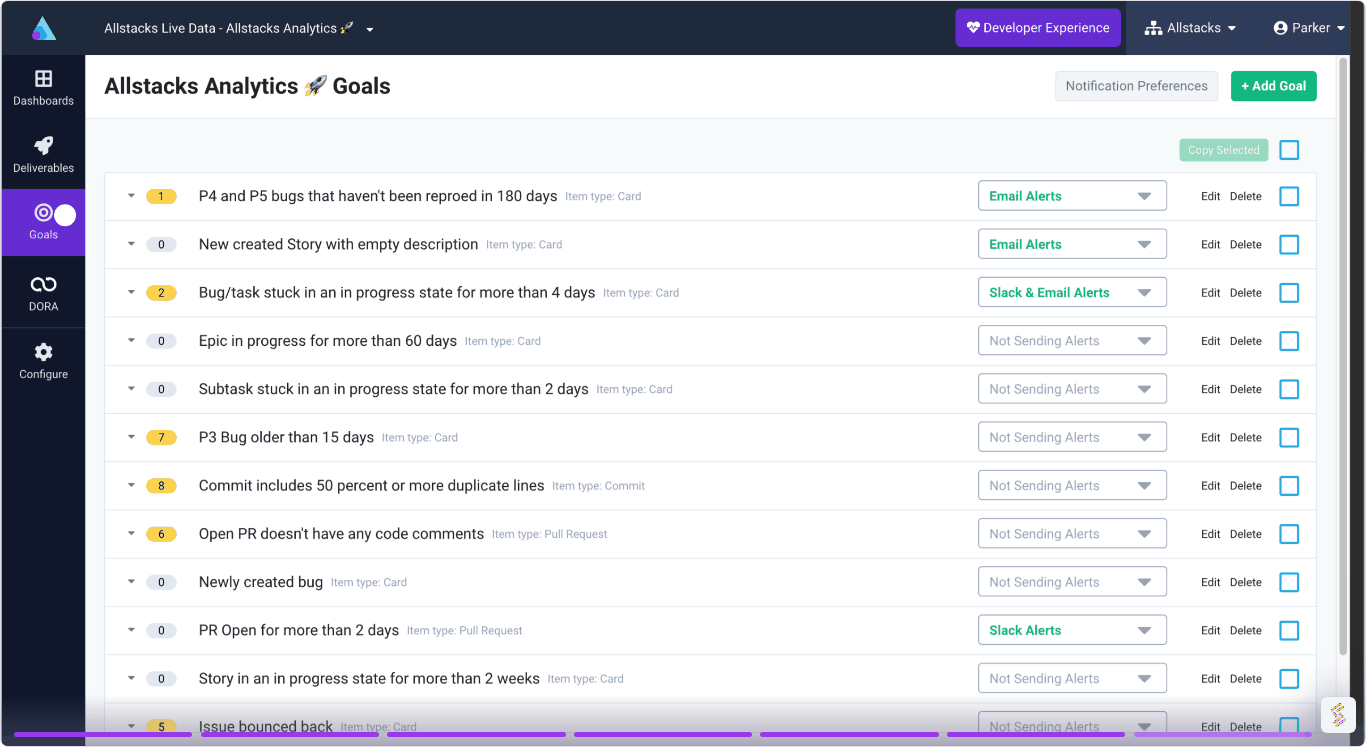
Complete visibility into time & dollars spent
-
 360º Insights
360º Insights
Create meaningful reports and dashboards
-
 Project Forecasting
Project Forecasting
Track and forecast all deliverables
Product Management
-
 Product Studio
Product Studio
Requirements building for agentic development
Software Capitalization
-
 R&D Capitalization Reporting
R&D Capitalization Reporting
Align and track development costs
Strategy & Thought Leadership
Stop Deleting Commits in Git
Squashing, rebasing, and syncing in Git: what's the best way to merge your code? We argue that at least one of these options isn't worthwhile

You have the consistency of one mainline branch that can be synced to a production environment while also the flexibility to go ham on building both long- and short-term feature building exercises. This flexibility is one of the reasons git is great, but it also means there are some strong opinions about how you have to structure things to work best with others.
I’m going to focus on one of the more contentious parts of this collaboration tool: branch management and merging. While there are a few popular modes of structuring your repository and working within it, I’ve seen very strong opinions in each mode about how, exactly, you should merge your code. There are three main patterns for doing it: Squashing, Rebasing, and Syncing. I make an ardent plea against one of them, which you may have guessed from the title.
Squash and Merge
The first approach to merging code is to squash [read: delete and replace] all of your work down into a single commit, and merge just one commit into the mainline branch. This has the advantages of easily thumbing through history and seeing each work item, as well as more easily removing layers if you need to remove code or features. It also results in a smaller repo with fewer cross merges which can make working in large teams easier.
The downside to squashing is actually in the deleting part. Realistically, you're deleting the history of how things were actually developed, and pretending like each feature popped up, fully formed, one random day in spring. If you’re tracking how things are developed, you may struggle to find or track that data after its’ gone. If you need to know the true history of how your teams develop features (and you really should be tracking it), you will lose all of that history.
Rebasing
Rebasing is the process of updating the commit that your work branches from. Rebasing has the advantage of incorporating full release checkpoints into your branch, giving you the time to address any conflicts before merging. You also are able to keep the full history of your work [with a few caveats], and keep your work in one chunk should it be merged in.
The downsides here are that you have a very long commit history, and are partially changing the git history (read up on committer dates vs. author dates to learn more). Most rebases also mess with git history tools due to the same date changes, and will treat all of your historical commits and added today at the same time. While it’s possible to extract all of the development history, it’s cumbersome.
Syncing
Syncing is the process of merging your main branch into your feature branch to reconcile your changes with the changes on the main branch. This has the advantage of recording each merge and set of changes to isolate specific changesets when you need to go figure out what happened to introduce a bug. It also preserves the history of your repositories almost exactly as they were created. By logging each merge action as a type of merge commit, you have the full history, warts and all, of how your features were developed.
The downsides here are that you’re in maximalist history-keeping mode. Everything is stored and mixed together on your final main branch. While it represents how you actually develop features, it’s almost impossible to follow and read the history. And should you need to roll back a large multi-commit feature? Get ready for git surgery.
Don’t delete commits
While there are many functioning teams where squashing is the rule, I strongly recommend you avoid any behaviors that delete history. As a strong proponent of tracking, sharing, and learning from metrics around how your team works and develops features, deleting that history removes most of that data, and leaves you guessing about how you’re improving or slipping.