Context Rot: Why Context Management Matters for AI
Every instinct says more context should mean better answers. The research on long-context performance says otherwise. This is the systems view of why, and what actually fixes it.

Key Takeaways
- Context rot: LLM output degrades as input grows, across all 18 models Chroma tested.
- Treat active context like an L1 cache: hold only the current working set.
- Relevance ranking loses the relationships between items. Those live in a context graph.
- MCP makes adding context free and removing it hard. Control what reaches the model.
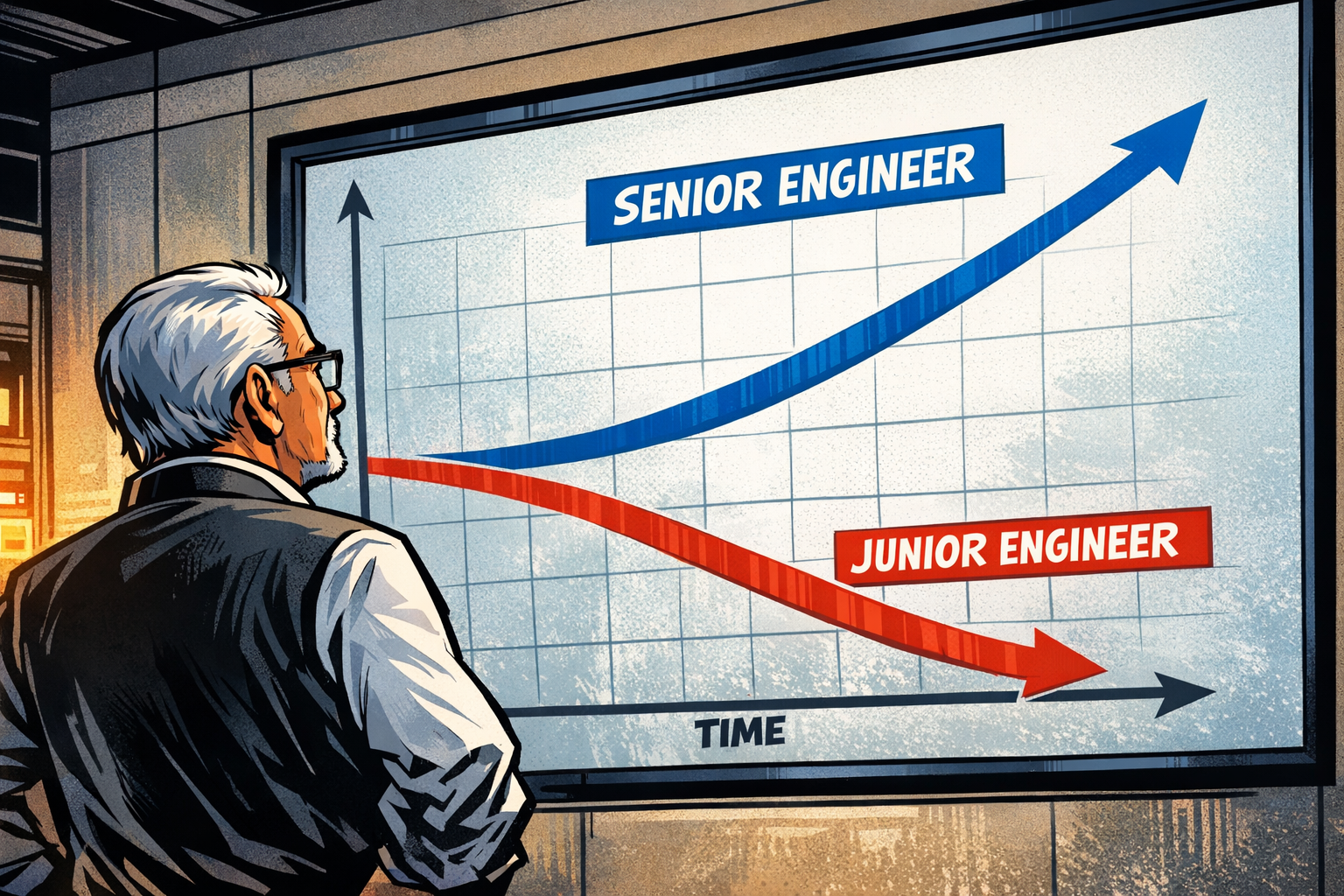
This runs against how most of us think about context. More context means more to work with, so more should mean better answers. When answers get worse, the natural read is that something was missing, and the fix is to add: a bigger window, more retrieved documents, more history. That's the wrong move. The trouble is rarely that there isn't enough context within reach. It's that almost none of it is the context the model needs right now.
The instinct to add has gotten much easier to act on. MCP servers have made it nearly free to plug new sources into an agent, and most teams now wire up a dozen without much thought: a ticketing server, a docs server, a code search server, a calendar, a CRM. Each one is a few lines of config, and each one widens the intake. The trouble is that they are one-way valves. They make more context available to pull in, and none of them come with a mechanism to push context back out once it's no longer useful. So the easiest thing in the stack to do is expand what the model sees, and the hardest thing, the thing nobody builds by default, is to contract it. The result is exactly the situation this piece is about: a tooling ecosystem optimized for adding, bolted onto models that quietly punish you for it.
What Causes Context Rot?
Context rot is the drop in output quality that comes from the length of the input, even when every token in it is relevant. Poor context management leads to context rot. The research is clear on this. Chroma's "Context Rot" report tested eighteen frontier models, including GPT-4.1, Claude 4, and Gemini 2.5, and every one degraded as input length grew, even on tasks simple enough that length should not have mattered. The decline is gradual rather than a cliff, and it shows up well before the window is full. A model with a 200K window can degrade noticeably at 50K. Two of their results stand out. When they held everything else constant and varied only length, accuracy still fell by several points, so even clean context costs something just by being long. And coherent, well-structured context degraded attention more than randomly shuffled context did. That last result cuts against the usual instinct: a tidy pile of mostly irrelevant context can hurt more than a messy one, because the problem is volume and density, not disorder. Capacity is the wrong thing to measure. Signal-to-noise is what sets output quality.
This holds up well beyond one vendor's report. The "lost-in-the-middle" research from Stanford found that models attend well to the start and end of their input and poorly to the middle, with accuracy falling more than thirty points depending on where the relevant fact sits. RULER and NoLiMa both showed that effective context, the length over which a model actually performs, runs far shorter than the advertised length, and the more recent minimum-effective-context-window work put sharper numbers on the same gap. A paper titled "Context Length Alone Hurts LLM Performance Despite Perfect Retrieval" isolated the effect: even when handed exactly the right evidence, with nothing missing, a model reasons worse when you pad the input. The mechanism is simple. Attention is a fixed budget spread across every token, so adding tokens thins the share each one gets. More input means less focus on each thing that matters.
Two forces are at work here:
Accretion is the pull to keep more. Dropping information feels risky, since you might need it later, so the easy path is always to append. Every retrieval system, growing chat history, and step-logging agent is an accretion engine that only adds.
Dilution is the cost of having kept more: relevance density drops, attention spreads, output degrades. The coherent-context finding is what makes this sting, because you can't organize your way out of it. A better-arranged pile doesn't help if the pile is too big, since volume itself is the tax. The only thing that helps is a smaller pile.
These pull in opposite directions, and most production systems manage only the first. Teams add retrieval and bigger windows to fight the fear of missing context, which is a real fear, while doing nothing about dilution, so they make the second problem worse while solving the first. What's missing is not better adding but selective forgetting, and forgetting is harder than it looks.
A Cache Model for Context Engineering
A cache hierarchy is a useful way to picture the fix. A CPU keeps a small, fast L1 cache for what it's actively using, backed by larger and slower L2 and L3, backed by main memory. It works because a program reuses a small set of data at any given moment, so keeping that set close pays off far beyond its size.
Context has the same shape. The active context a model reasons over is L1: small, fast, and the only thing it truly operates on. Everything else the session has gathered belongs in slower tiers, pulled up only when the current task needs it. The goal is to hold the working set, the things in use right now, and keep the rest one tier down, reachable but out of the way.
It's a good model, and it's also a little too comforting. The point where it stops being accurate is the point where the real difficulty starts.
The analogy flatters the situation in a second way. A cache controller sits inside the processor with direct control over what gets evicted and when. You have nothing like that. When you build on a model you call through an API, you don't control its attention, you can't evict anything from its context, and you can't see what it actually used. The only lever you have is the text you assemble and pass in on the next turn. Every technique below has to be carried out through that one opening, from outside a system, you don't get to open up, which is most of what turns the straightforward-sounding ideas into real work.
Fix One: Rank and Trim (Context Pruning)
If the problem is too much in the window, the obvious move is to prune: score everything by relevance, keep the top, drop the rest. It's the first thing most people reach for.
It breaks down quickly. A flat keep-the-top-N throws away a distinction you need, because context doesn't sort cleanly into "in" and "out." There's a middle: material you don't need active now but will likely need soon, which should be demoted and kept cheap to recall rather than dropped. A top-N cut collapses that middle, and you lose the tier that makes the approach work.
The next idea is to make pruning dynamic and prune when output quality drops. But quality is a trailing signal. You only know the output got worse after it's generated and shipped, so you'd be steering by the rearview mirror, and wiring that into a live loop makes it oscillate: cut too much, quality drops, add back, dilute, cut again. What you need is a leading signal that tells you when to reconsolidate before the damage reaches the output. Such a signal exists, but finding and tuning it is real work, made harder by the fact that you can't watch what the model attends to from the outside, only what it finally produces.
Fix Two: Rewrite the Summary (Context Reconsolidation)
Rather than trim a list, reconsolidate. Keep one running summary of the working set, rewrite it as the task moves, and demote the raw material underneath. This maps onto the cache analogy directly: evict from the fast tier, recall when needed.
This is where the cache analogy breaks, and the break matters more than anything else here.
A hardware cache is lossless. The line you evict to L3 comes back bit-for-bit identical, which is why eviction is safe: nothing changes in the round trip. A reconsolidated summary is not a copy. It's a rewrite, and a rewrite drops things. Compressing the working set into a fresh summary means judging what to keep and what to cut, and sometimes you cut something the task needs three steps later. Nothing flags it. The summary still reads well. It's simply missing the one fact that mattered, and you won't find out until a downstream answer is wrong in a way you can't trace back.
To do this safely, you have to know whether a given reconsolidation lost anything that mattered, which means measuring fidelity: did the rewrite keep everything later turns depended upon. The only honest way to measure that is to replay real sessions and check whether information dropped at one step was needed several steps later. That requires an evaluation harness built on real session data, and the harness, not the forgetting logic, is where most of the engineering lives. Because you can't see inside the model, that harness is a black box by necessity: you replay sessions and judge the outputs, with no direct readout of what the model actually leaned on. That's a slower and noisier thing to build on than it sounds.
Most teams realize they need that harness only after shipping the lossy version and fielding bug reports they can't reproduce.
Fix Three: Add the Relationships (Context Graphs)
Everything so far treats context as a pile of text to be managed by relevance. But what often makes a recommendation good is the relationships between items: that one is the root cause behind a cluster of others, that fixing one resolves five, that this one blocks that one. Lose those and the system treats connected things as unrelated.
The obvious approach is to put the relationships into the context, and it has its own complications. What the model reads is often not what you assembled, because structure tends to break down at the boundary between your system and the prompt, surviving only as prose the model then has to re-infer. Even once you fix that, you have to decide where the relationships live and what it costs to assemble them every turn, and the traversals involved are usually expensive enough that computing them live is a non-starter and the work has to move offline.
The real lesson here is about sequencing. Relationships are a second, narrower problem than dilution, and the skill is refusing to let them pull focus from the issue that dominates output quality. Most of the difficulty in this work is not in solving any single problem but in knowing which ones are load-bearing, in what order, and which are interesting distractions.
What a Solution Looks Like
The shape of a solution is fairly clear, even if building it well is not. A few principles hold up across all of the above.
Treat the active context as a working set, not an archive. What the model reasons over should hold what the current task is using, and nothing more. Everything the session has gathered still exists, one tier down, reachable on demand. It's the cache instinct: keep L1 small and let the slower tiers carry the bulk.
Reconsolidate instead of append. Almost every system defaults to adding, because adding is easy and dropping feels risky. Maintain one current, canonical view of the task and rewrite it as the task moves, instead of stacking new material on old. Rewriting is what lets you drop what's no longer relevant; appending never does.
Make forgetting recoverable. Demote rather than delete, so pushed-down material stays addressable and can be pulled back when the task turns toward it again. Forgetting you can reverse is safe to do aggressively; forgetting you can't is a liability.
Measure the forgetting. This is the step teams skip and the one that matters most. You can't tune any of the above by intuition, because the failure mode is invisible: a summary that dropped something important looks identical to one that didn't. The only way to know is to replay real work and check whether what you dropped was needed later. The measurement layer isn't an add-on at the end; it's the foundation the rest stands on, and most of the actual engineering.
Keep the relationship problem in its place. Relationships matter, but they're narrower than raw dilution and best handled as a separate layer derived in the background rather than computed live. Fix the thing that dominates output quality first, and don't let the more interesting problem jump the line.
The challenge is in the systems design. These parts have to operate together: a policy that decides what to keep, a leading signal for when to reconsolidate, a recall path cheap enough to run inside the loop, and an eval harness that can show a given reconsolidation didn't drop anything that mattered. Each is manageable on its own, and much harder once they run in parallel and have to stay consistent with one another. The loop also runs entirely around a model you don't control. You can't reach its attention or its context handling. You can only change the text you pass in on the next turn, and you can only judge the result by what comes back. How much of that you can touch depends on where you build: inside a finished assistant, the context assembly happens for you, so you have less to work with than on the API, where at least the assembled prompt is yours. Building and tuning a control system under those constraints, against a signal you read from the outside, is where the engineering time goes.
Is the MCP Boom Making Context Rot Worse?
The MCP boom is already exposing this gap. Adding a server takes a few lines of config, and the ecosystem keeps making intake easier. Every new source widens the flood, and none of the easy tooling touches the harder job underneath: deciding what the model should look at right now, and proving that what you cut didn't cost you. The teams that pull ahead won't be the ones wired to the most sources. They'll be the ones who control what actually reaches the model.
Frequently Asked Questions
What is context rot?
Context rot is the drop in an LLM's output quality as its input grows longer, even when the context window is nowhere near full. More tokens going in produces worse reasoning coming out. Chroma's research tested 18 frontier models and found every one degraded as input length increased, often well before the advertised window filled.
Why does an AI agent get worse even when the context window isn't full?
Attention is a fixed budget spread across every token in the window. Each token you add takes a share of that budget away from the tokens that matter, so reasoning thins out as the input grows. The window measures capacity; it says nothing about how well the model attends across everything inside it.
What is the difference between context engineering and prompt engineering?
Prompt engineering shapes the single instruction you give the model. Context engineering shapes everything else the model sees: what gets retrieved, what carries over from earlier turns, and what gets dropped. Gartner named context engineering the successor to prompt engineering in 2025, because in agentic systems what reaches the model decides the outcome more than the phrasing of any one instruction.
Does adding more MCP servers make context rot worse?
It can. Each MCP server widens what an agent can pull in, and most add tool definitions that consume tokens whether or not they get used. MCP makes adding context nearly free, but nothing about it removes context once that context stops being useful, so the default path is always to expand what the model sees. The more sources you connect, the more controlling what actually reaches the model matters.
How do you fix context rot?
Treat the active context as a working set that holds only what the current task needs, and keep everything else one tier down, reachable on demand. Reconsolidate that working set as the task moves instead of appending to it, keep the forgetting recoverable so demoted material can come back, and measure what each rewrite drops so you can tell a safe summary from a lossy one. The measurement step is the one most teams skip and the one that decides whether the rest holds up.
Table of contents
![Half of Product & Engineering Say Ticket Quality Is Causing Drag [Webinar Recap]](https://cdn.prod.website-files.com/6a392acd5ecae4670660e882/6a44ab11abe712ac1a3cd374_AI%2520Developer%2520Sorting%2520Jira%2520Tickets%2520into%2520Robot%2520with%2520Bad%2520Slop%2520Output-1.png)

/ get started /
