Why Your Roadmap Is Slipping Has Nothing to Do With Your PMs
Roadmaps are slipping in AI-coding orgs but sprint attainment looks fine. The bottleneck moved upstream to spec quality. Here's the failure sequence and what to check this week.

Jeff Keyes
Field CTO & Product Leader
Date
June 4, 2026
Tags
Strategy & Thought Leadership
If you're a VP of Product watching launch dates go red in week six on features that looked safe in week one, the temptation is to look at the transition between product and engineering. Maybe the discovery wasn't tight enough. Maybe the requirements needed another review cycle. Maybe engineering overcommitted.
The problem today is likely upstream of delivery.
I work with engineering and product orgs that have rolled out AI coding tools at scale, and the pattern I see is consistent enough to name directly: roadmap slip in 2026 traces to a bottleneck that moved upstream from engineering throughput to spec quality. Product execution is where the blame lands. The root cause is elsewhere.
The two reports that describe the same problem
Pull up two things from your last quarter. First: the sprint attainment data from your engineering teams (story points committed at planning versus story points delivered, week over week). Second: the epic burndown on your roadmap view, or the list of features that missed their launch dates.
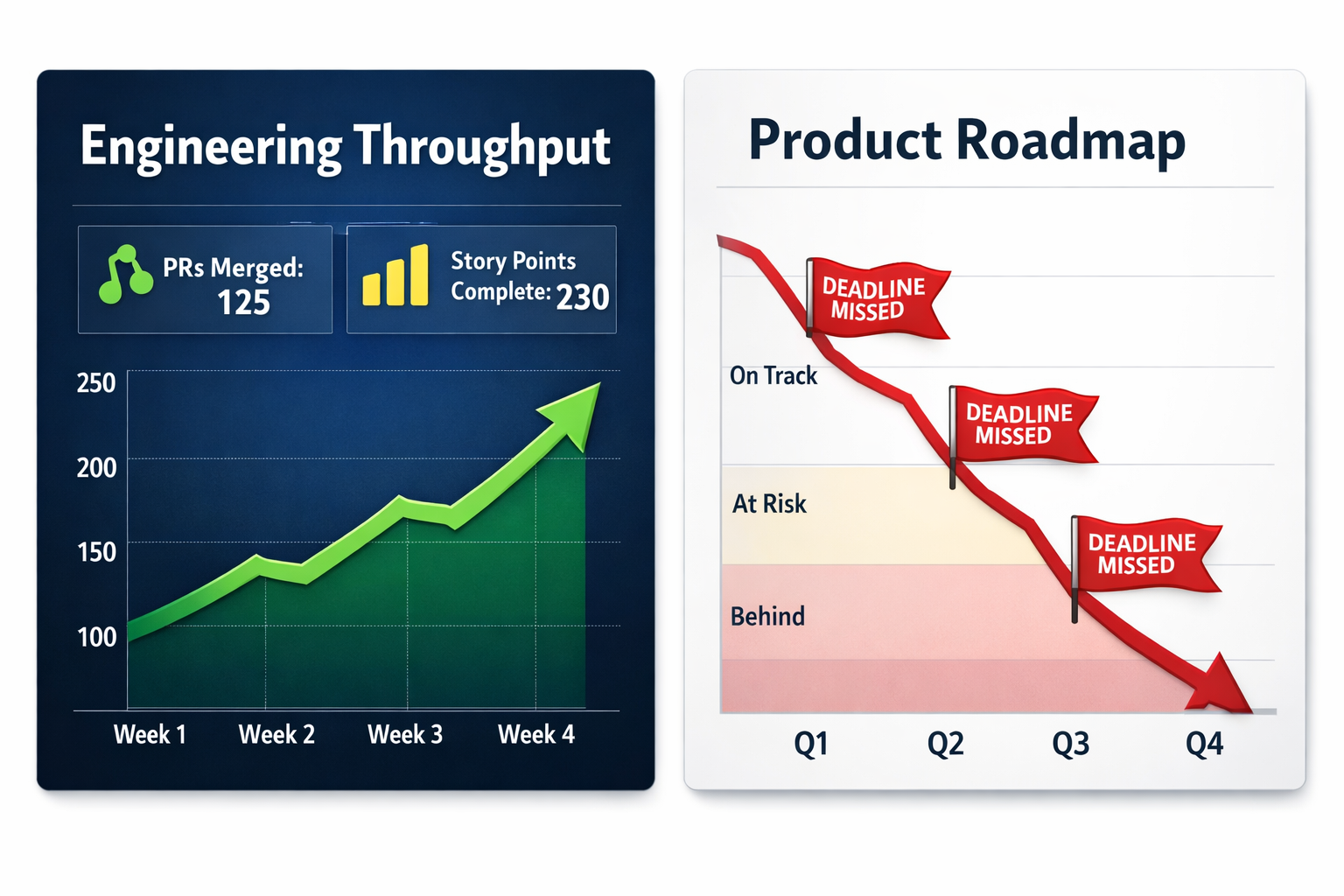
In most AI-coding orgs right now, those two views describe what looks like two different realities.
The sprint attainment data shows a healthy team. Velocity is steady, PRs are merging, and story points are closing. The teams that rolled out Copilot, Cursor, or Claude Code are showing measurably higher output per engineer. The AI investment looks like it's working, and it is working at the level it's measured.
The roadmap view tells a different story: quarterly commitments slipping, launch dates that looked safe at planning going red around week six, and the credibility of estimates eroding quarter over quarter. You're either padding forecasts to the board (and getting called a sandbagger) or trusting engineering's numbers and getting blindsided.
Both reports are accurate, and neither shows you what actually went wrong.
What the standard Jira reports don't capture
Your sprint attainment chart measures story points closed. It does not measure whether the closed work built the right thing. Your velocity chart measures throughput, not whether that throughput is going toward your roadmap or toward rework.
When a team discovers mid-sprint that a brownfield dependency wasn't in the spec, the sprint attainment data doesn't register a problem. The discovery might be a deprecated API still live in three places, a feature toggle nobody cleaned up, or a shared service that behaves differently from what the ticket assumed. The team is still working. Velocity numbers look fine. The status your PM reports is green.
What changes is the scope. Three sprints becomes six. That shows up on your roadmap as a slipped launch four or five weeks after the discovery, usually just before a board update.
The earliest signal of that slip was never in the Jira reports you're looking at.
What changed when AI coding tools landed
For the last two decades, engineering throughput was the constraint. PMs wrote specs that opened the conversation with engineering rather than closed it. Grooming was where the spec got finished: engineers pushed back, surfaced missing context, and turned ambiguous requirements into something buildable. That conversation was the safety net.
AI coding tools collapsed the cost of writing software. Cursor, Claude Code, Copilot, and the rest of the stack dropped the per-line cost of code to near zero for a competent senior engineer. Industry research published in recent months has affirmed what a lot of engineering leaders are living: individual developer output climbed, while organizational delivery velocity stayed flat or regressed. The teams using AI tools are shipping more code. The roadmaps are still slipping.
The bottleneck moved. It didn't disappear.
Engineering can now write code faster than ever. Defining the right code to write became the operational constraint. AI coding agents execute against whatever spec they receive without asking that question, including the missing edge cases, the vague acceptance criteria, and the architectural assumptions nobody documented. The gap that used to surface in grooming now surfaces in a PR review, after the code is written.
Before AI coding tools, an experienced engineer would catch a brownfield conflict and raise it. Now the agent builds without asking.
Why brownfield codebases make this expensive
In a greenfield codebase, a spec gap is annoying but recoverable. The agent invents some patterns, your senior engineer catches it in review, you absorb some rework.
In a brownfield enterprise codebase, the spec gap is expensive. The context that matters most for any new feature is architectural: which services already handle this concern, which APIs return what shape, which feature toggles are still active, which auth paths are deprecated but still live in production, which past decisions shaped why the area looks the way it does. None of that lives in a Confluence page. None of it lives in the original ticket. It lives in engineering's collective memory and in the code itself.
Your PM wrote the spec from what they knew. Increasingly, they used AI assistance to draft it, which sharpens the prose but doesn't make it any more realistic or buildable without breadth and depth of context. The AI coding agent reading that spec doesn't have the necessary context either. It codes against the input it has.
Roadmap credibility breaks down at the gap between what the spec says and what the codebase actually requires. That gap is not in your PM's drafting process.
The diagnostic worth running this week
Before your next quarterly planning conversation, do one thing. Pull the last three features that slipped from a clean estimate to a missed launch. For each one, ask the engineer who built it what they discovered after sprint planning that wasn't in the original spec.
The answers will cluster. An architectural dependency nobody flagged at planning. An API that didn't behave the way the ticket assumed. A deprecated path still running in production. A feature toggle that should have been removed years ago. In every case: the information was in the codebase. It wasn't in the spec. It didn't show up in the sprint attainment data until the scope had already expanded.
That clustering is your signal. The slip pattern isn't random and it isn't your PMs. Getting codebase context into the spec before it leaves the planning surface is the upstream fix; stricter process templates don't reach the root cause. What that looks like in practice is what Part 2 of this series covers.
Table of contents



/ get started /
