







In our second post in the series, we heard how Krish uses analytics in his leadership. Namely, how data-based insights enable a healthy team culture and strategic alignment across the business. Now we’re taking the controversial topic of data visibility head-on to discover why Krish advocates for this principle, both within engineering and across business functions.
It’s no secret that engineers get weary at the mention of metrics. The idea is often associated with performance evaluation and the fear that raw numbers fail to provide the complete picture of value, process, and complexity, which isn’t untrue. Worse still, data can be over-leveraged or misinterpreted to support punitive measures against teams and individual contributors. At Allstacks, we encourage using data to gain visibility into project status to keep work on track, to advocate for and to understand where your teams need support, and to facilitate collaboration across departments.
Lesson #3: Learn to love — and use data.
Talking with Krish, we found a kindred spirit in improving how engineering uses analytics and data-driven insights to create better visibility for everyone involved in software delivery. Here’s what he had to say:
On looking at the right data...
It's natural for engineers to be wary of how data is used when talking about "performance;" metrics like code volume can be intimidating and misleading. We worry they will be used to measure individual performance. This is exactly why current measures like lines of code, velocity, or even the DORA metrics shouldn't be used in a vacuum or without additional context.
Instead, we should look for insight into how teams work — like the type of items worked on, work patterns, team sentiment, etc. These insights can inform the progress of initiatives, identify risks such as capacity concerns and identify areas for process improvement. Not to stack-rank developers on isolated metrics. The end game is to gain visibility into work to deliver strategic business outcomes and maintain the team's overall satisfaction.
On data accessibility...
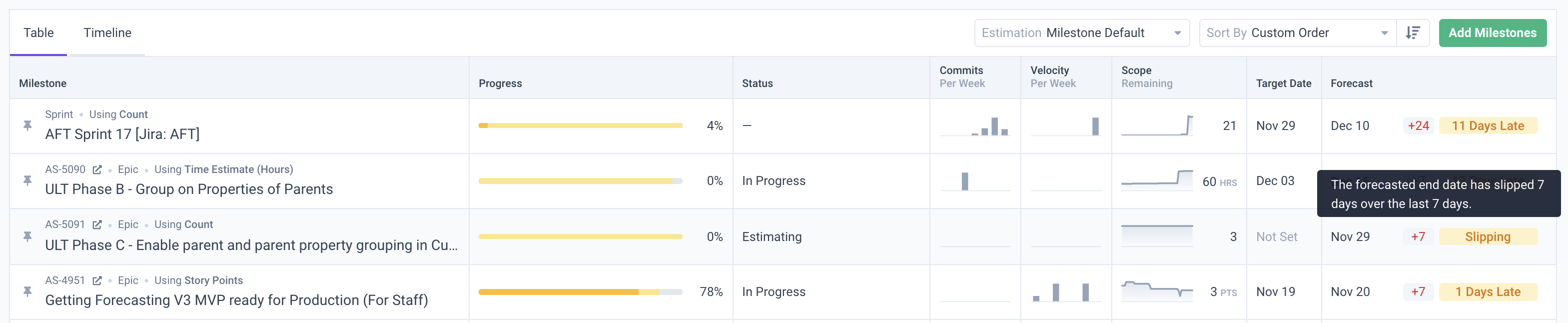
Simply having access to this data should be table stakes for software leaders and stakeholders. But it turns out, getting that access isn’t so simple. This information lives in tons of disconnected systems or lacks enough context to be helpful. I have found that the data and reports in SDLC tools like JIRA create more questions than they answer and are generally unhelpful at telling the true story of progress. Not to mention that each team could have a different JIRA instance that makes rolling up reporting across groups impossible. I convinced our team to give me database access to JIRA because I was so frustrated with what information was available in our tools.
For example, the standard JIRA burndown is ineffective because different teams have different “definitions of done.“ When you look at it, it only tells the story from one perspective. Because there is no connection between code commits and JIRA project management (other than a plug-in that shows you which commit is attached to which ticket). There is no way to get analytics from it, context into progress, or a way to really investigate what is happening.
Some unfortunate person ends up tasked with manually pulling this information together, likely with some massive spreadsheet and SQL query. Then that person has to translate between teams if we will deliver on time and, if not, where things got off track. Which often is too late because it took too long.
On multiple levels of decision-making...
Technology leaders need to make data-based decisions at multiple levels daily:
- At the executive level, we’re talking business strategy to answer what will add the most significant value to the product suite and setting expectations with high-level release timelines.
- We then have to make practical decisions about what issues or work to prioritize to get closer to the business’s goals and expectations.
- Figuring out how we’re going to accomplish the work.
- And if things get off track - what work gets dropped?
Each decision-making level requires different inputs and is associated with various tools, resources, people, and metrics. All of this is amplified when you have multiple products, teams, methodologies, etc. It becomes impossible to get a quick and consistent report on what is going on at each level and roll that information up to executives and product stakeholders.
Having a single source of truth that rolls up all the relevant data from across teams and disparate sources helps me quickly get a pulse on a project and answer the various questions about progress, risks, or team health.
On using Allstacks to solve these challenges...
We use Allstacks to put this impossibly complex puzzle together for us. Allstacks automatically combines information from our teams, tools, and projects to contextualize the data in real-time. This gives me and other stakeholders insights into changing delivery dates, what’s going well, and what needs my support to keep the momentum going forward on the right things proactively.
(You can see this best through the Portfolio Report. You can go through the interactive tour here.)
One practical way Allstacks helps with teams’ having different definitions of done is by breaking up your burndown into the different workflow states in JIRA. This allows us to quickly find the bottleneck and provides the metrics to tell me if we are getting better or not. If we aren’t getting better, I know we have some process improvements we need to invest in. If we are getting better, I know our improvements are making an impact, and we can further reinforce those processes.
Another way Allstacks helps us is to use our data to predict or forecast when projects will be complete. This also allows us to validate our estimates. If our estimates are way off, we know we need to reexamine our priorities and requirements to ensure we are correctly scoping work.
On the future of intelligent data analysis...
There isn’t going to be a job in 25 years that doesn’t involve technology. The ability to predict the future based on historical data and trends is already here. Soon, the entire value stream will be planned, forecasted, and measured automatically. Data aggregation and intelligent analysis of that data will be how all decisions are made. Technologists, computer scientists, and engineers will be in higher demand everywhere, from marketing to customer service and other traditionally ‘non-technical areas. All areas of the business will be continuously optimized.
Our ability to pool, analyze, and share data and insights will determine how optimized and innovative we can get and how quickly we can move the business forward. This doesn’t mean swapping human labor for automation or creating an Orwellian society. Instead, it makes room for better, more strategic business decisions and efficiencies that allow people to be productive and fulfilled in their jobs.
Want to hear more from Krish? Check out the other spotlights in this series:
/new-Path266.svg)
like this? share it: